
STA 2000 笔记
统计学笔记,仅作为个人学习记录,不保证正确性。
Index
- Index
- Chapter 1: Defining and Collecting Data
- Chapter 2: Organizing and Visualizing Variables
- Chapter 3: Numerical Descriptive Measures
- 3.1 Measures of Central Tendency
- 3.2 Measures of Variation
- 3.3 Shape of a Distribution
- 3.4 Quartile Measures
- 3.5 Five Number Summary
- 3.6 Numerical Descriptive Measures for Populations
- 3.7 Empirical Rule
- 3.8 Chebyshev's Rule
- 3.9 Covariance
- 3.10 Correlation Coefficient
- 3.11 Pitfalls in Numerical Descriptive Measures
- Chapter 4: Basic Probability
- Chapter 5: Discrete Probability Distributions
- Chapter 6: The Normal Distribution
- Chapter 7: Sampling Distributions
- Chapter 8: Confidence Interval Estimation
- Chapter 9: Fundamentals of Hypothesis Testing: One-Sample Tests
- Chapter 10: Two-Sample Tests and One-Way ANOVA
Chapter 1: Defining and Collecting Data
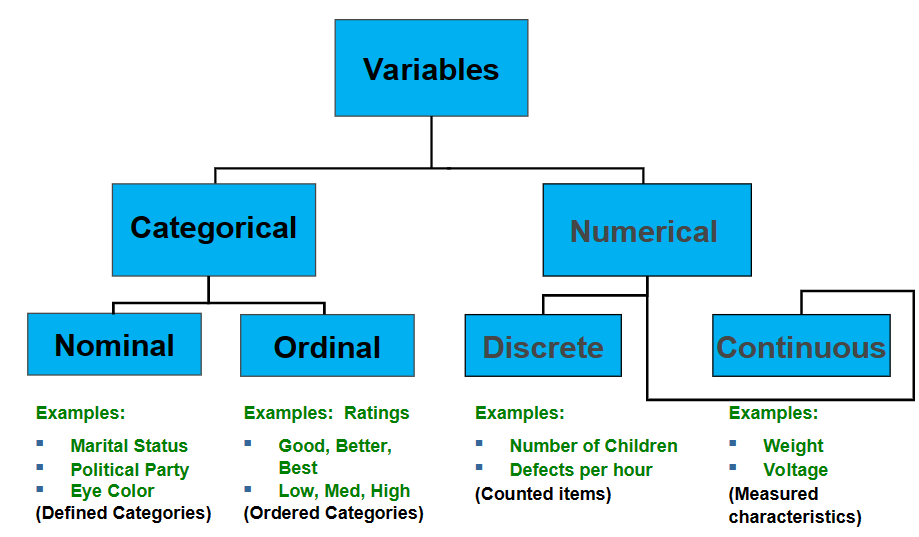
1.1 Variables
Categorical(qualitative): a variable that can be placed into a specific category, according to some characteristic or attribute.
- Nominal: no natural ordering of the categories
- Ordinal: natural ordering of the categories
Numerical(quantitative): a variable that can be measured numerically.
- Discrete: arise from a counting process
- Continuous: arise from a measuring process
1.1.1 Measurement Scales
Interval scale: an ordered scale in which the difference between measurements is a meaningful quantity but the measurements do not have a true zero point.
Ratio scale: an ordered scale in which the difference between measurements is a meaningful quantity and the measurements have a true zero point.
1.2 Population and Sample
Population: the set of all elements of interest in a particular study.
- contains all measurements of interest to the investigator
Sample: a subset of the population.
- a part of the population selected for analysis
1.2.1 Parameter and Statistic
Population parameter: a numerical measure that describes an aspect of a population.
Sample statistic: a numerical measure that describes an aspect of a sample.
1.2.2 Sources of Data
Primary sources: data that are generated by the investigator conducting the study.
- from a political survey
- collected from an experiment
- observed data
Secondary sources: data that were produced by someone other than the investigator conducting the study.
- analyzing census data
- examining data from print journals or data published on the Internet
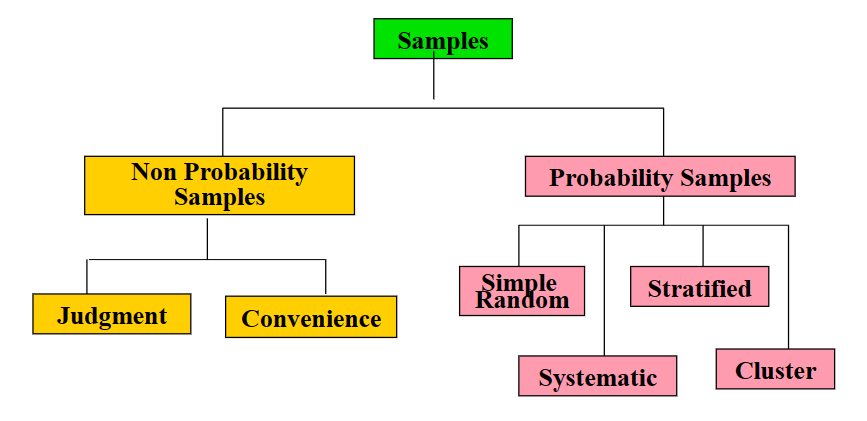
1.2.3 Probability Sample
In a probability sample, items in the sample are chosen on the basis of known probabilities.
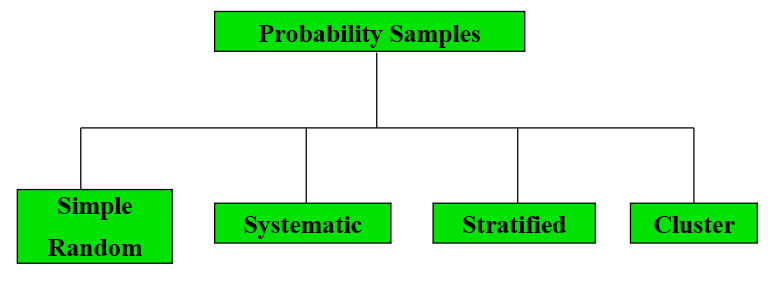
- Simple random sample: every individual or item from the frame has an equal chance of being selected
- Systematic sample: the items are selected according to a specified time or item interval in the sampling frame
- divide frame of
- divide frame of
- Stratified sample: divide population into two or more subgroups(strata)according to some characteristic that is important to the study
- Cluster sample: population is divided into several "clusters" or sections, then some of those clusters are randomly selected and all members of the selected clusters are used as the sample
Chapter 2: Organizing and Visualizing Variables
2.1 Organizing Categorical Data
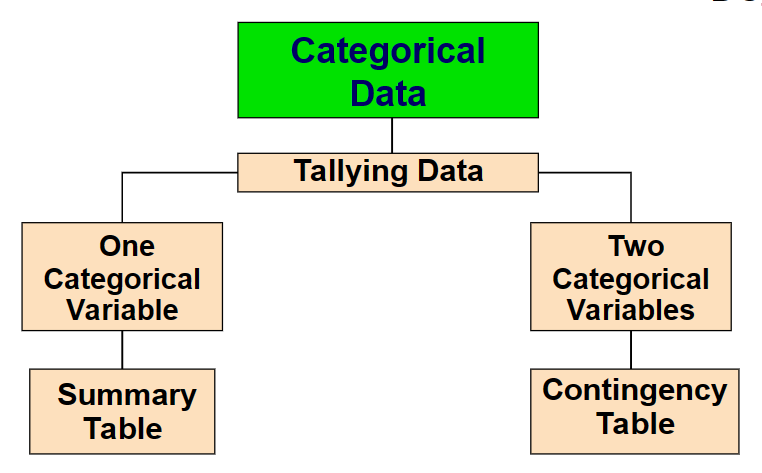
- Summary table: tallies the frequencies or percentages of items in a set of categories so that you can see differences between categories
- Contingency table: a table that classifies sample observations according to two or more identifiable categories so that the relationship between the categories can be studied

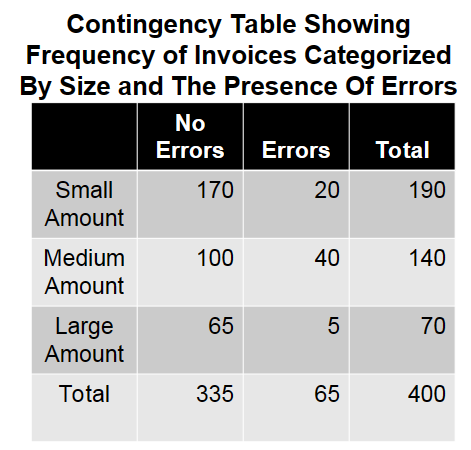
2.2 Organizing Numerical Data
- Ordered array: a sequence of data, in rank order, from the smallest value to the largest value.
- Frequency distribution: a summary table in which the data are arranged into numerically ordered classes
2.3 Visualizing Categorical Data
- Bar chart: visualizes a categorical variable as a series of bars
- Pie chart: a circle broken up into slices that represent categories
- Doughnut chart: the outer part of a circle broken up into pieces that represent categories
- Pareto chart: a vertical bar chart, where categories are shown in descending order of frequency
- Side by side bar chart: a bar chart that compares two or more categories
- Doughnut chart(contingency): a doughnut chart that compares two or more categories
2.4 Visualizing Numerical Data

- Stem-and-leaf display: a simple way to see how the data are distributed and where concentrations of data exist
- Histogram: a vertical bar chart of the data in a frequency distribution
- Percentage polygon: formed by having the midpoint of each class represent the data in that class and then connecting the sequence Of midpoints at their respective class percentages
2.4.1 Visualing Two Numerical Variables
- Scatter plot: used for numerical data consisting of paired observations taken from two numerical variables
- Time series plot: used to study patterns in the values of a numeric variable over time
Chapter 3: Numerical Descriptive Measures
Central tendency: the extent or inclination to which the values of a numerical variable group or cluster around a typical or central value.
3.1 Measures of Central Tendency
Measure of central tendency: a single value that attempts to describe a set of data by identifying the central position within that set of data.
3.1.1 Mean
3.1.2 Median
- Sample size is odd:
- Sample size is even:
3.1.3 Mode
Mode: the value that occurs most frequently in a data set.
3.2 Measures of Variation
Measure of variation: gives information on the spread or variability or dispersion of the data values.
3.2.1 Range
3.2.2 Sample Variation
Sample variance: average of squared deviations of values from the mean.
3.2.3 Sample Standard Deviation
3.2.4 Coefficient of Variation
3.2.5 Z-Score
Z-Score: the number of standard deviations that a given value
- a data value is considered an extreme outlier if its Z-Score is less than -3 or greater than +3
3.3 Shape of a Distribution
3.3.1 Skewness
Skewness: a measure of the degree of asymmetry of a distribution.
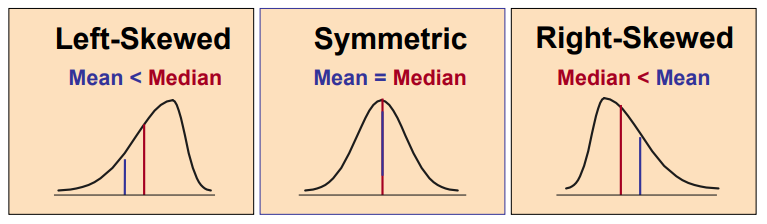
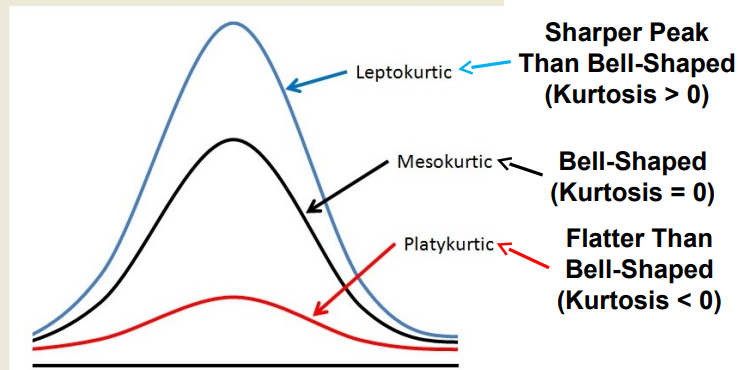
3.3.2 Kurtosis
Kurtosis: a measure of the degree of peakedness of a distribution.
3.4 Quartile Measures
Quartile: a value that divides a data set into four groups containing(as far as possible)an equal number of observations.
3.4.1 Locating Quartiles
3.4.2 Interquartile Range
Interquartile range: the difference between the third and first quartiles.
3.5 Five Number Summary
Five number summary: the five numbers that help describe the center, spread and shape of data.
3.5.1 Relationships Among the Five Number Summary and Distribution Shape
| Left-Skewed | Symmetric | Right-Skewed |
|---|---|---|
3.5.2 Boxplot
Boxplot: a graphical display of the five number summary.
3.6 Numerical Descriptive Measures for Populations
3.6.1 Population Mean
3.6.2 Population Variance
3.6.3 Population Standard Deviation
3.7 Empirical Rule
Empirical rule: approximates the variation of data in a symmetric mound-shaped distribution.
- 68% of the data values lie within one standard deviation of the mean
- 95% of the data values lie within two standard deviations of the mean
- 99.7% of the data values lie within three standard deviations of the mean
3.8 Chebyshev's Rule
Chebyshev's rule: applies to any data set, regardless of the shape of the distribution.
- at least
3.9 Covariance
Covariance: a measure of the linear association between two variables.
3.10 Correlation Coefficient
Correlation coefficient: a measure of the linear association between two variables.
3.10.1 Features of the Correlation Coefficient
The population coefficient of correlation,
The sample coefficient of correlation,
3.11 Pitfalls in Numerical Descriptive Measures
- Data analysis is objective
- Data interpretation is subjective
Chapter 4: Basic Probability
Sample space: the set of all possible outcomes of an experiment.
4.1 Events
Simple event: an event described by a single characteristic or an event that is a set of outcomes of an experiment.
Joint event: an event described by two or more characteristics.
Complement of an event A:
- all events that are not part of event A
4.2 Probability
Probability: the numerical value representing the chance, likelihood, or possibility that a certain event will occur.
- always between 0 and 1
Impossible event: an event that has no chance of occurring.
Certain event: an event that is sure to occur.
Mutually exclusive events: events that cannot occur at the same time.
Collectively exhaustive events: the set of events that covers the entire sample space.
- one of the events must occur
4.2.1 Three Approaches to Assigning Probability
A priori probability: a probability assignment based upon prior knowledge of the process involved.
- Example: randomly selecting a day from the year 2019. What is the probability that the day is in January?
Empirical probability: a probability assignment based upon observations obtained from probability experiments.
- Example:
Subjective probability: a probability assignment based upon judgment.
- differs from person to person
4.2.2 Simple Probability
Simple probability: the probability of a single event occurring.
4.2.3 Joint Probability
Joint probability: the probability of two or more events occurring simultaneously.
4.2.4 Marginal Probability
Marginal probability: the probability of a single event occurring without regard to any other event.
| Total | |||
|---|---|---|---|
| Total | 1 |
4.2.5 General Addition Rule
General addition rule: the probability of the union of two events is the sum of the probabilities of the two events minus the probability of their intersection.
If
4.2.6 Conditional Probability
Conditional probability: the probability of an event occurring given that another event has already occurred.
- The condition probability of
- The condition probability of
- where
4.2.7 Independent Events
Independent events: two events are independent if the occurrence of one event does not affect the probability of the occurrence of the other event.
- events
4.2.8 Multiplication Rule
Multiplication rule: the probability of the intersection of two events is the product of the probability of the first event and the conditional probability of the second event given that the first event has occurred.
If
Chapter 5: Discrete Probability Distributions
Probability distribution: a listing of all the outcomes of an experiment and the probability associated with each outcome.
5.1 Expected Value
Expected value: the mean of a probability distribution ->
5.2 Variance and Standard Deviation
Variance: the average of the squared deviations of the possible values from the expected value.
Standard deviation: the square root of the variance.
Chapter 6: The Normal Distribution
6.1 Continuous Probability Distributions
Continuous variable: a variable that can assume any value on a continuum(can assume an uncountable number of values)
For example, the thickness of an item, the time required to complete a task.
6.2 Normal Distribution
Normal Distribution:
- bell shaped
- symmetrical
- mean, median and mode are equal
The location is determined by the mean,
The random variable has an infinite theoretical range:
6.2.1 Density Function
Probability density function: a function whose integral is calculated to find probabilities associated with a continuous random variable.
6.2.2 Standardized Normal
Standardized normal distribution: a normal distribution with a mean of 0 and a standard deviation of 1.
Its density function is:
6.2.3 Normal Probabilities
Probability is measured by the area under the curve.
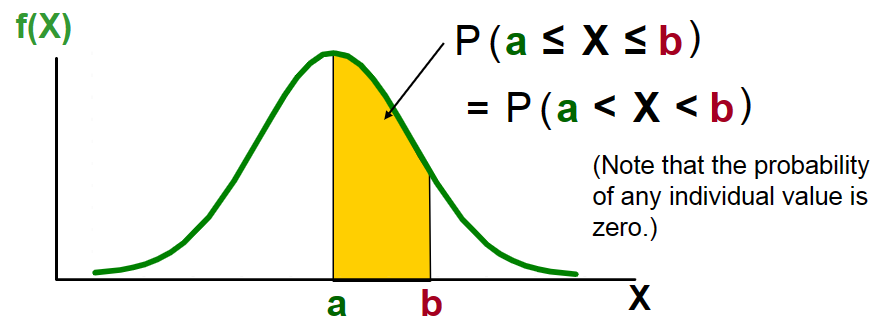
Uniform Distribution: a continuous probability distribution in which the probability of observing a value x in any interval of equal length is the same for each interval of the same length. Also known as rectangular distribution.
Exponential Distribution: a continuous probability distribution that is used to describe the time between events that occur at a constant average rate and are independent of each other. The exponential distribution is skewed to the right.
Chapter 7: Sampling Distributions
Sampling distribution: a distribution of all of the possible values of a sample statistic for a given sample size selected from a population.
Assume there is a population:
- population size
- variable of interest is,
, age of individuals - values of
: (years)
7.1 Sample Mean Sampling Distribution
7.1.1 Standard Error of the Mean
Standard error of the mean: the standard deviation of the sampling distribution of the sample mean.
7.1.2 Z-Value for Sampling Distribution of Mean
7.1.3 Sampling Distribution Properties
- The mean of the sampling distribution of the sample mean is equal to the mean of the population
- As
7.1.4 Central Limit Theorem
Central limit theorem: the sampling distribution of the sample mean is approximately normal for a sufficiently large sample size.
- as the sample size gets large enough, the sampling distribution of the sample mean becomes almost normal regardless of shape of population
Central limit theorem is used when the population is not normal.
How large is large enough?
- for most distributions,
is sufficient - for fairly symmetric distributions,
is sufficient - for a normal population distribution, the sampling distribution of the sample mean is always normally distributed
7.2 Population Proportions
Sample proportion(
7.2.1 Sampling Distribution of the Sample Proportion
7.2.2 Z-Value for Proportions
Chapter 8: Confidence Interval Estimation
8.1 Point and Interval Estimates
Point estimate: a single number.
Confidence interval: a set of two plausible values at a specified confidence level that contains true parameter.
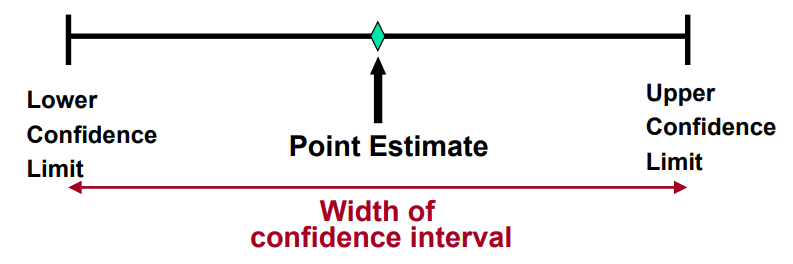
8.2 Confidence Intervals
Interval estimate: provides more information about a population characteristic than does a point estimate -> confidence intervals.
Chapter 9: Fundamentals of Hypothesis Testing: One-Sample Tests
Hypothesis: a claim or assertion about a population parameter.
Example:
The mean diameter of a manufactured bolt ismm ->
9.1 The Null Hypothesis
- begin with the assumption that the null hypothesis is true
- similar to the notion of innocent until proven guilty
- represents the current belief in a situation
- always contains
- may or may not be rejected
9.2 The Alternative Hypothesis
- is the opposite of the null hypothesis
- the mean diameter of a manufactured bolt is not equal to
- challenges the status quo
- never contains the
- may or may not be proven
- is generally the hypothesis that the researcher is trying to prove
9.3 The Hypothesis Testing Process
The population mean age is
.
Suppose the sample mean age was
.
This is lower than the claimed mean population age of. If the null hypothesis were true, the probability of getting such a different sample mean would be very small, so you reject the null hypothesis.
In other words, getting a sample mean of
is so unlikely if the population mean was , you conclude that the population mean must not be .
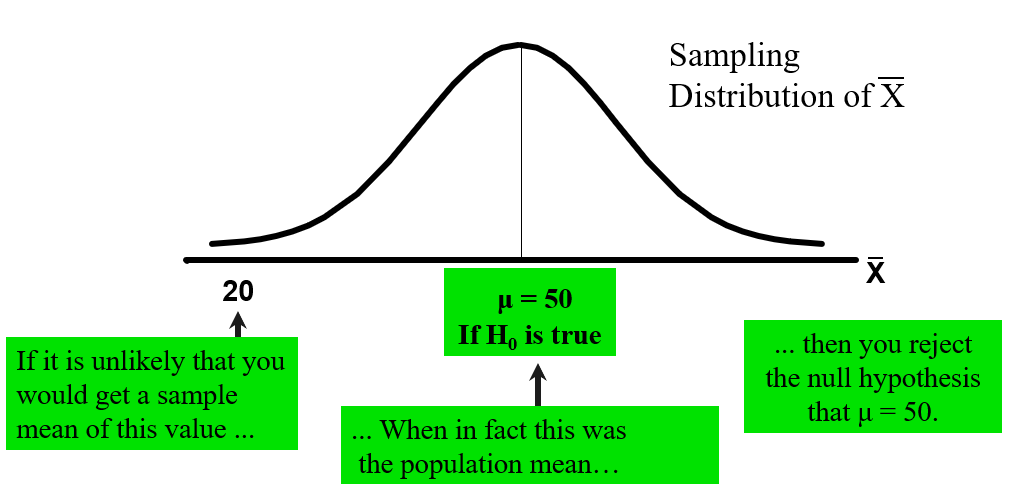
9.3.1 The Test Statistic and Critical Values
If the sample mean is close to the stated population mean, the null hypothesis is not rejected.
If the sample mean is far from the stated population mean, the null hypothesis is rejected.
How far is "far enough" to reject
The critical value of a test statistic creates a "line in the sand" for decision making -- it answers the question of how far is far enough.
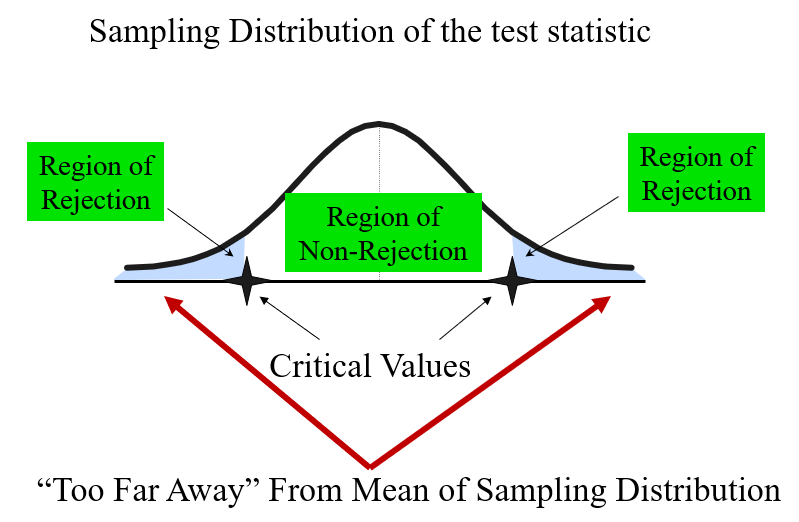
9.3.2 Risks in Decision Making Using Hypothesis Testing
- Type I error: rejecting the null hypothesis when it is true
- a "false alarm"
- the probability of a Type I Error is
- called level of significance of the test
- set by researcher in advance
- Type II error: failing to reject the null hypothesis when it is false
- a "missed opportunity"
- the probability of a Type II Error is
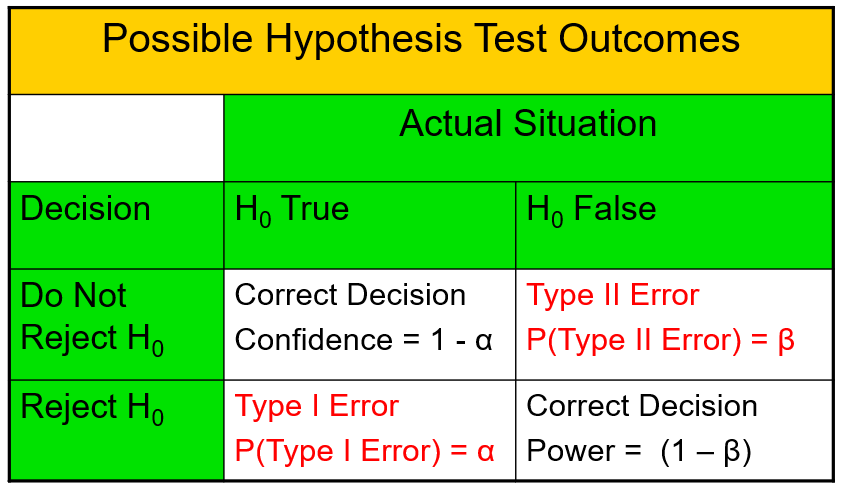
- the confidence coefficient is
- the confidence level of a hypothesis test is
- the power of a statistical test
Type I and Type II errors cannot happen at the same time.
- A Type I error can only occur if
- A Type II error can only occur if
Factors affecting Type II Error:
All else equal……
when the difference between hypothesized parameter and its true value when when when
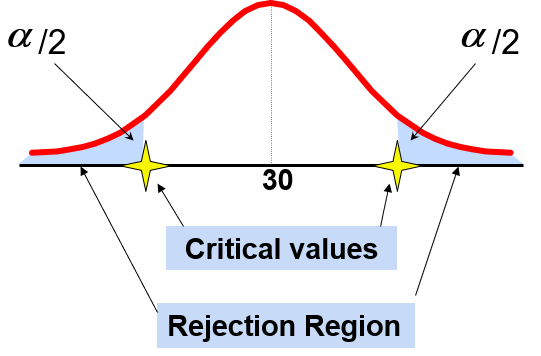
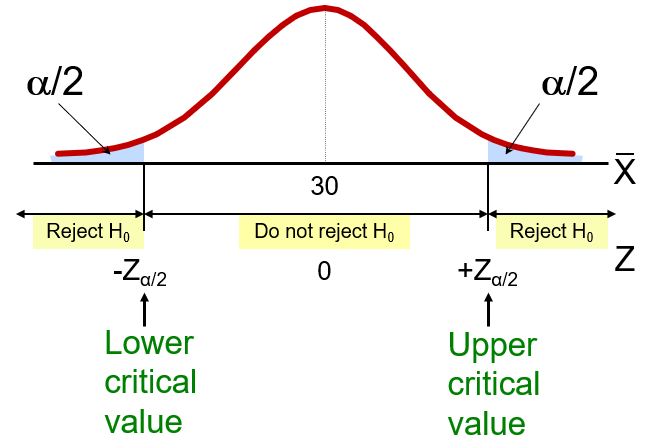
9.3.3 Level of Significance and the Rejection Region
Level of significance =
This is a two-tail test because there is a rejection region in both tails.
9.4 Hypothesis Tests for the Mean
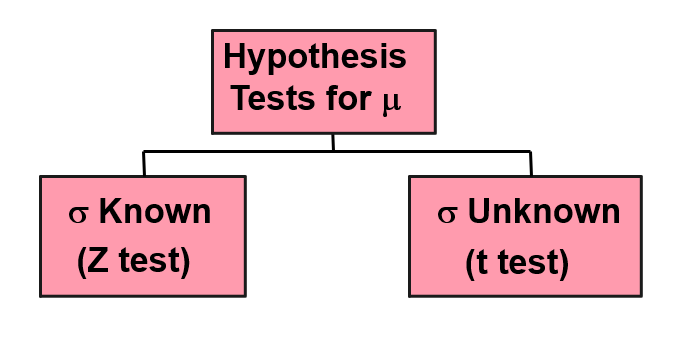
9.4.1 Z Test of Hypothesis for the Mean
Convert sample statistic(

For a two-tail test for the mean,
known:
- determine the critical
values for a specified level of significance from a table or by using computer software
Decision rule: if the test statistic falls in the rejection region, rejectotherwise do not reject
Chapter 10: Two-Sample Tests and One-Way ANOVA
10.1 Two-Sample Tests
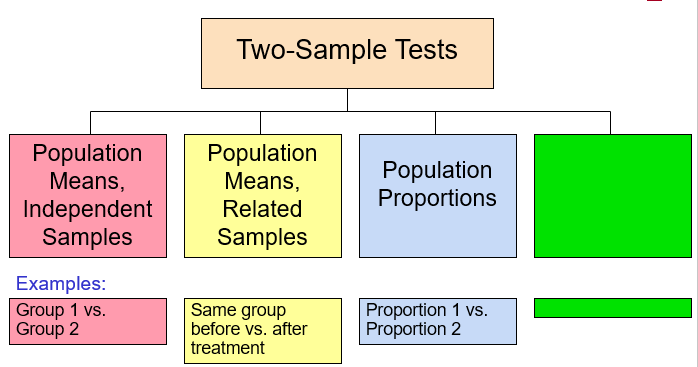
10.1.1 Difference Between Two Means
To test hypothesis or form a confidence interval for the difference between two population means,
The point estimate for the difference is: